Scaling Laws in Deep Learning

“Scaling law” sounds technical, but it’s pretty straightforward: make ‘em bigger, feed ‘em more, they get better (unlike us who actually start functioning slower after a burrito with extra chicken). Well, mostly.
Physics Dropping Knowledge (Again)
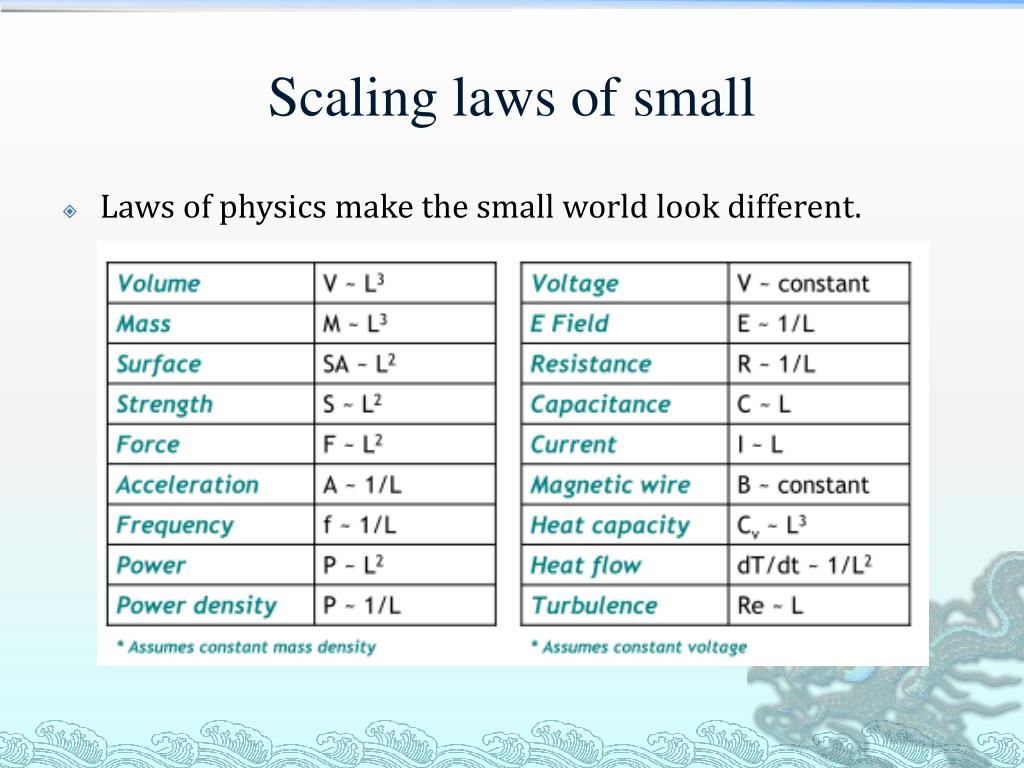
Believe it or not, the notion of scaling isn’t exclusive to deep learning. Physicists have long observed that as you increase the size or energy of a system, its behavior changes in predictable—and sometimes dramatic—ways. Imagine heating a single water droplet versus a whole pot of water: the boiling process isn’t just a scaled-up version of what happens in that tiny droplet. That’s the vibe we’re talking about in AI. This predictability in change is the essence of scaling laws in physics, and it provided the inspiration for AI researchers to ask: what happens if we just keep making our neural networks bigger and better?
Early Clues: Translation Was Onto Something
Turns out, scale was the secret sauce. Back in the day, researchers were wrestling with machine translation. And they noticed, the bigger the model, the more data it saw, the better it translated. Duh! But it was a big deal at the time.
This paper from 2014, “Sequence to sequence learning with neural networks”, kinda hinted at this. Sutskever, Vinyals, and Le showed that bigger “sequence-to-sequence” models, trained on loads of text, just translated better. No “scaling laws” label yet, but the scale effect was obvious.
The Scaling Laws Paper: Formulas and Stuff
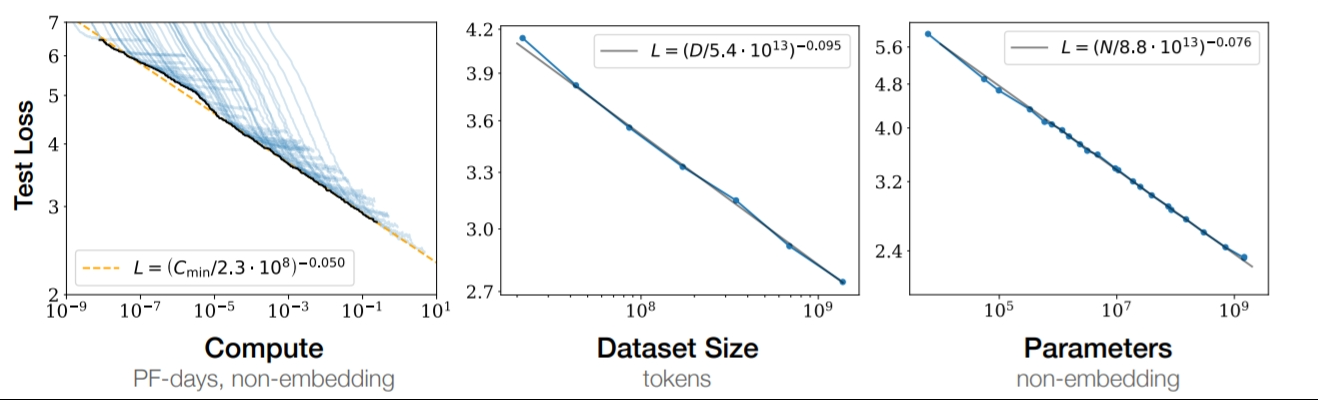
Then, 2020 rolls around, and OpenAI drops “Scaling Laws for Neural Language Models”. Kaplan and co. actually put numbers on this scaling thing. Formulas, even.
Turns out, performance improves predictably when you scale:
- Model Size (N): Bigger brain. More connections. You get it.
- Dataset Size (D): More data gives the model a richer tapestry of patterns to learn from.
- Compute (C): The raw horsepower behind the training process.
They even gave us some rough formulas, showing loss goes down as you crank up N, D, and C. Numbers like αN ≈ 0.076, αD ≈ 0.095, αC ≈ 0.050 floating around. In other words, the more you invest in these areas, the better your model gets—but with diminishing returns as you push the limits.
Smarter Scaling is a Thing
So, just keep making models huge? Not exactly. DeepMind chimed in 2022 with the “Chinchilla scaling” idea. Paper’s called “Training compute-optimal large language models” if you’re digging deeper. Basically, they argued maybe we were making models too big, not using data efficiently. They suggested for the same compute, you might be better off with a slightly smaller model but way more data. Smarter scaling, not just brute force. It’s a bit like cooking stew: you can’t just pile on ingredients without considering how they blend together. Efficient scaling is about striking the right balance rather than simply reaching for the largest pot with every condiment thrown in.
Scale still rules, but it’s nuanced. It’s about balancing size, data, and compute. People are still figuring out the details:
- Inference Compute: Giving models more “think time” even after training can boost performance.
- Better Architectures: Designing models that are just inherently better learners, getting more bang for your buck from data and compute.
- Beyond Simple Formulas: Power laws are cool, but maybe there’s more to the story. Sadly, the compute to do such analysis isnt available to every independent researcher :’(
Are We Gonna Max Out?
Though scaling’s been good to us, it poses the question if we are then heading for an “information ceiling?” Basically, is there only so much info out there to train on? Once AI’s seen it all, does scaling even matter anymore?
Debate’s still raging. But some things to consider:
- Data Quality is King: More data isn’t always better data. Crappy data in, crappy AI out.
- Emergence vs. Understanding: These models are doing impressive stuff. But are they actually understanding, or just mimicking patterns? Scaling might not bridge that gap. (Emergence is a way cooler and mystical enigma if you are interested!)
- Compute Costs (Planet Too): Training these monsters is expensive and energy-hungry. Endless scaling wouldn’t be so sustainable.
Some fallacies learned by LLMs:
We’ve all seen generative models tweaking and tripping, which (unless they are purely diffusion-models) funnily enough, also use transformer architectures as backbone.
- Them fingers: Motion of legs is bad, and fingers are rendered even worse. I honestly haven’t found a reasonable answer, but there are theories.
- Dial Clocks: All of them show 10 past 10, since all models were trained with watch faces available in the internet. See for yourself.
- Wine in glass: All of them are half full, aren’t they? Same. Pictures from the internet.
- Maths and “Strawberry”: One of the reasons openAI’s O1 was code-named strawberry was likely a reference to the infamous problem of initial LLMs not getting how many r’s are in the word “strawberry”. Believe it or not, LLMs sucked at maths for the same reason (kinda): Tokenization.
There is a ceiling from the data available to us so far, since we have used most of them up! New research will move towards new ways to make AI truly intelligent, not just… big. It’s gonna be interesting, we are finally going to move past the overhyped stuff.
References:
- Sutskever et al. (2014): “Sequence to sequence learning with neural networks” - Early hints of scale’s power in translation.
- Kaplan et al. (2020): “Scaling Laws for Neural Language Models” - The scaling laws bible.
- Hoffmann et al. (2022): “Training compute-optimal large language models” - Scaling, but make it efficient.